Face expression
recognition
Luka Pavlović

Saša Brdnik

Ivan Šimac
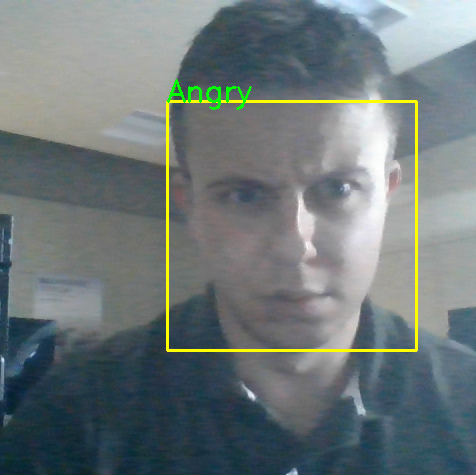
Recognize facial expression as angry, disgust, fear, happy, neutral, sad, surprise from image
Dataset
We used Jonathan Oheix's relatively widely used Face expression recognition dataset of 35.9k images. Images were tagged with one of the seven required emotions (anger, disgust, fear, happiness, neutral, saddness, surprise) and organized in training and validation dataset. Dataset uses consistent 48x48 pixel grayscale images of faces. The faces have been automatically registered so that the face is more or less centered and occupies about the same amount of space in each image.

Challenges along the way
- the images have a low resolution
- Some images have text written on them
- Some people hide part of their faces with their hands
- Eyeglasses on certain subjects
- Automatic cropping
- Contrast variation


Results
- Successfully included the dataset.
- Trained and tweaked our model to 63% accuracy.
- Expanded our model to live camera recognition.
- Improved the model to recognize emotions even if person is wearing a facial mask.
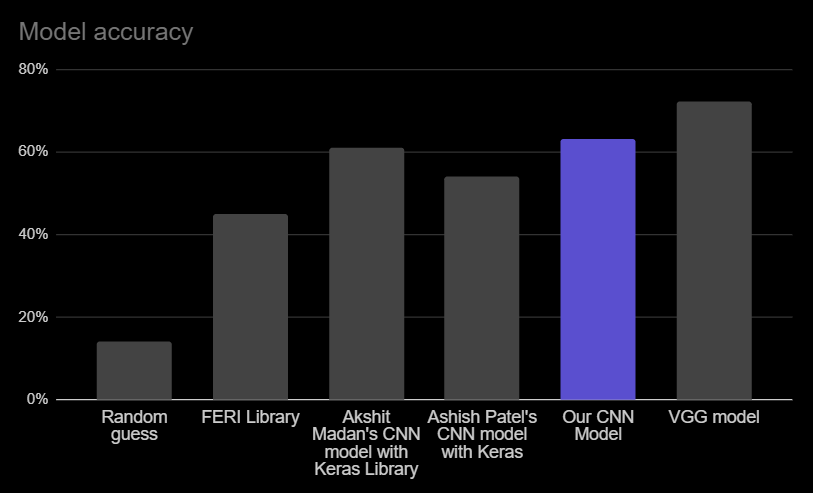
Model comparison
The accuracy of compared models is presented in the graph below.
It is clearly visibly we have improved the accuracy of some models, by more than 10%, while we could
still not reach the current state-of-the-art accuracy of VGG model.
Detailed comparison of selected Convolutional Neural Network (CNN) models
We compared three different models. Keras Library was used in all three cases, along with Jonathan Oheix's Face expression recognition dataset of 35.9k images.
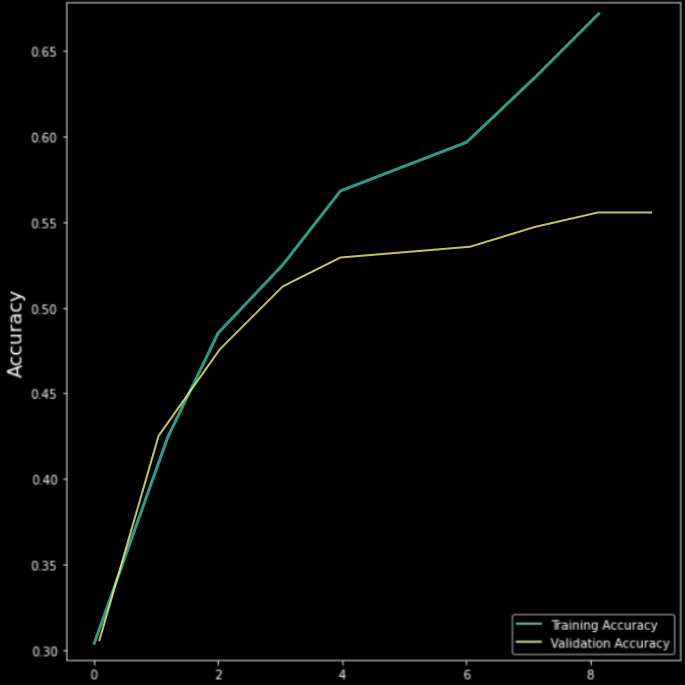
Ashish Patel's Model (for comparison)
Total params: 779,767
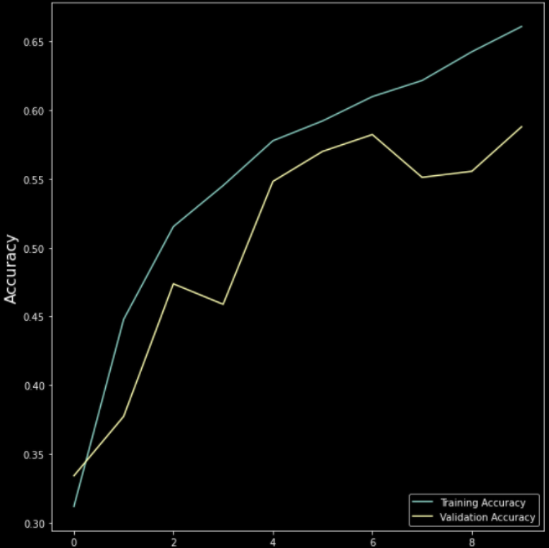
Akshit Madan's Model (for comparison)
Total params: 4,478,727
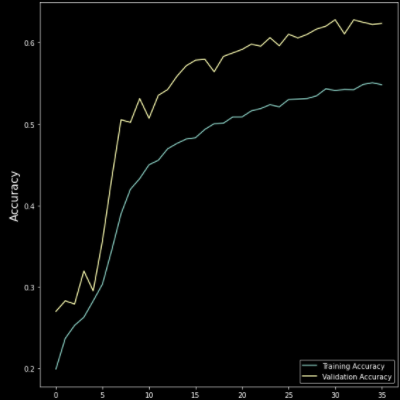
Our model
Total params: 1,328,167
Report
Our team has also:
- Tried out various libraries - FER, Keras, etc.
- Compared the proposed model to other existing models, posted on the web by different authors.
- Included the model in the live camera recognition.
- Presented a solution, which works also with facial masks.